
Création de fichiers de données à partir de tableaux publiés
Fichiers de données créés par l'IRCS à partir d'une sélection de tableaux publiés
Pour chaque recensement de 1911 à 1951, le Bureau fédéral de la statistique (aujourd'hui Statistique Canada) a publié un ensemble de volumes et de tableaux. À partir de ces volumes, l'IRCS a choisi et informatisé 23 tableaux traitant de thèmes comme la population (effectifs répartis par sexe), le nombre de demeures, de ménages et de familles ainsi que la religion ou l'origine ethnique des individus. Cette section décrit brièvement le traitement informatique effectué par l'IRCS et l'interface offerte pour la consultation.
1. Création des fichiers numérisés et vérification des données
Ces 23 tableaux publiés ont été numérisés puis convertis en fichiers de données brutes au moyen d'un logiciel de reconnaissance optique de caractères (OCR), Abbyy FineReader. On a procédé ensuite à la vérification visuelle systématique de toutes les valeurs des données saisies. Enfin, des tests de fiabilité ont été faits à l'intérieur de chaque fichier et, dans certains cas, entre les fichiers.
Une soixantaine de tests de contrôle ont été ainsi effectués. Pour la grande majorité d'entre eux, l'opération consiste à soustraire de l'effectif total les valeurs de toutes les variables (ou colonnes) publiées, le résultat devant être 0. Certains tests concernent des variables exprimées en pourcentage ou donnant la mesure d'une superficie, ce qui implique différents types de formules de vérification.
En outre, l'IRCS vérifie que la somme des données pour l'échelle géographique de base est égale à la valeur indiquée pour l'unité immédiatement supérieure dans la hiérarchie géographique. En d'autres termes, si l'unité géographique de base figurant dans un tableau est la subdivision de recensement (SDR), la somme des données pour les SDR est comparée à la valeur indiquée pour la division de recensement (DR) ; pour les tableaux dont l'unité de base est la DR, la comparaison se fait entre la somme des données de la DR et la valeur indiquée pour la province. Cependant, aucune vérification n'est effectuée directement au niveau de la province ou du Canada si l'unité de base du tableau est la SDR.
On fait des vérifications entre fichiers par exemple pour confirmer que les effectifs de population par origine ethnique ou par religion correspondent aux effectifs de population par sexe. Ce type de vérification n'est pas effectué systématiquement pour chaque année de recensement dans toutes les provinces, mais plutôt lorsqu'un test de contrôle décèle une irrégularité non typographique.
Si la majorité des irrégularités est effectivement de nature typographique, l'utilisateur doit cependant être au courant de certaines autres anomalies. Ainsi, dans les tableaux publiés de l'année 1911 pour la province de Québec, nous avons trouvé 11 SDR pour lesquelles la population totale diffère d'un tableau de recensement à l'autre (le tableau 1 ci-dessous présente trois de ces cas). La plupart de ces cas sont manifestement des erreurs survenues à l'étape de la compilation par des agents d'Ottawa en 1911, lorsque le district (secteur de dénombrement) d'un recenseur a été inclus dans une SDR donnée pour le tableau de population totale et dans une autre SDR pour un autre tableau. C'est ce qui est arrivé à Saint-Maurice et à Saint-Narcisse : 654 personnes ont été comptées dans l'un pour le tableau de la population totale et dans l'autre pour les tableaux de la religion et de l'origine ethnique. Il est aussi arrivé (apparemment une seule fois dans le recensement de 1911 pour le Québec) qu'un secteur de dénombrement soit purement et simplement oublié dans une compilation, comme dans le cas de la SDR Notre-Dame-de-Québec.
Tableau 1 : Résultats de certains contrôles de vérification effectués sur les tableaux publiés numérisés, province de Québec, 1911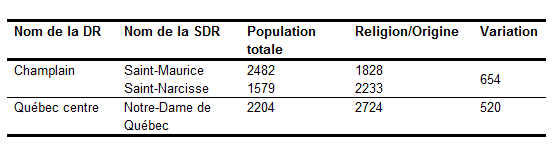
Nom de la DR Nom de la SDR Population totale Religion/Origine Variation
Champlain Saint-Maurice 2482 1828 654
Saint-Narcisse 1579 2233
Québec centre Notre-Dame de Québec 2204 2724 520
Source : Recensement du Canada, 1911, Volume 1, Tableau 1 et Volume 2, Tableaux 2 et 7
Pour les tableaux 1 et 2 du volume 1 de 1911, l'IRCS a eu accès aux corrections manuscrites d'un employé du Bureau du recensement (A.J. Pelletier), qui l'ont beaucoup aidé à résoudre certains problèmes touchant les données. Dans le but de fournir la meilleure information possible aux utilisateurs, l'IRCS a effectué quelques changements aux valeurs publiées en se servant des corrections de Pelletier en plus des contrôles de vérification. Chaque fois qu'une valeur publiée est modifiée par l'IRCS, la raison en est indiquée dans le champ NOTES, avec la valeur publiée d'origine. Ainsi, si un utilisateur veut connaître la valeur publiée à l'origine, il n'a pas à consulter le volume.
Notons que le champ NOTES a deux usages bien particuliers. Il sert d'abord à noter exactement les notes de tableaux qui figurent dans les volumes publiés. Il sert aussi aux commentaires de l'IRCS sur la valeur d'une rangée ou d'une cellule particulière. Il est facile de faire la différence : le texte ajouté par l'IRCS est toujours en italique et commence par IRCS :. Certaines notes peuvent contenir les deux types d'information, celle du Bureau du recensement et celle de l'IRCS. L'utilisateur notera également que toutes les notes ont une version en français et une version en anglais.
Aucun livre de corrections manuscrites n'existe pour les autres années (1921 à 1951) ; par conséquent, les modifications aux valeurs sont issues des contrôles de vérification. Dans la mesure du possible, l'IRCS donne la référence des autres volumes publiés ou des tableaux qui étayent ces changements. Les utilisateurs noteront que l'IRCS n'effectue des modifications qu'à deux conditions : une preuve d'inexactitude et une valeur alternative. Si l'IRCS ne peut pas fournir de valeur alternative, une note éventuelle avertit l'utilisateur que la valeur publiée semble incorrecte.
En conclusion, l'utilisateur devrait noter que parfois il pourrait y avoir des différences entre les valeurs publiées et les effectifs attendus pour certaines variables en fonction de la structure de l'échantillon de l'IRCS. Par exemple, le nombre de demeures fourni par le Bureau du recensement peut différer de l'identification faite par l'IRCS. L'utilisateur devra tenir compte de ces grands principes et de ces mises en garde lorsqu'il travaillera avec les tableaux publiés numérisés mis à sa disposition par l'IRCS.
2. Structure des fichiers de données provenant des tableaux publiés
Les fichiers de données provenant des tableaux publiés numérisés contiennent diverses variables agrégées à plusieurs niveaux géographiques différents, depuis les subdivisions et divisions de recensement (SDR et DR) jusqu'à la province et à l'ensemble du Canada. La première ligne de chaque fichier indique les noms abrégés des variables alors que la seconde présente les données pour l'ensemble du Canada. Ensuite, les données relatives à chaque province, ainsi que leurs DR et leurs SDR respectives, sont présentées. Les provinces sont répertoriées dans le même ordre que celui de la publication d'origine correspondante : soit d'est en ouest, soit par ordre alphabétique.
Les intitulés peuvent différer d'un tableau à l'autre même pour des tableaux provenant de la même année de recensement et de la même échelle géographique. Par exemple, dans un même volume, deux tableaux à l'échelle des SDR peuvent ne pas comporter exactement la même liste de SDR parce que le Bureau des statistiques a agrégé les données différemment pour les deux tableaux au moment de leur compilation. C'est pourquoi chacun des tableaux transcrits par l'IRCS possède sa propre structure de codes, qui peut être mise en relation avec les fichiers des polygones IRCS ainsi qu'avec les données échantillonées de l’IRCS.
Les champs de chaque fichier sont organisés selon l'ordre suivant:
1) Champs d'identification
2) Valeurs des données
3) Notes
Nous avons déjà vu quel était le contenu des notes dans la section précédente de ce texte, et les champs correspondant aux valeurs des données ne nécessitent pas d'explication. Les champs d'identification méritent, eux, quelques éclaircissements. Le premier est le champ ROW_ID, un identifiant unique de ligne (row) numéroté de façon séquentielle. Chaque fichier de données provenant des tableaux publiés numérisés par l'IRCS contient également, dans la deuxième colonne, un champ d'identification spécifique associé au tableau (p. ex. V1T1_1911), qui est la clé de la correspondance géographique entre les valeurs des données et les autres composantes IRCS (le fichier de données de l'échantillon et les fichiers des polygones). D'autres champs d'identification peuvent être utilisés, selon le niveau auquel l'utilisateur veut agréger les données. Pour plus de détails, vous pouvez consulter la liste complète des variables et de leur libellé d’origine.
Les libellés d'origine sont en fait ceux des tableaux publiés, sans adaptation aux libellés en vigueur d'aujourd'hui. Les colonnes n'étant cependant pas toutes libellées en français et en anglais, l'IRCS a fourni systématiquement un libellé dans les deux langues.
L'IRCS a tenté de garder les mêmes noms de divisions et de subdivisions de recensement (DR et SDR) d'un fichier de données publiées à un autre. À quelques exceptions près, les noms des entités géographiques sont donc exactement tels qu'ils figurent dans les volumes publiés. L'utilisateur est invité à considérer les noms qui paraissent dans les tableaux numérisés comme les noms en usage pour ces entités au moment du recensement. Ces noms peuvent être différents de l'identification des polygones dans les fichiers du SIG, ces derniers étant davantage standardisés (pour plus de détails, consulter le reste de la section Traitement spatial IRCS).
Le champ CSD_TYPE identifie le type de SDR. Il n'est complété que lorsqu'une valeur lui est attribuée dans le tableau publié ; ce n'est pas le cas pour la plupart des SDR.
Voici la significations des codes de la variable CSD_TYPE :

* Le code CSD_TYPE peut être suivi de la chaîne _PT, qui signifie que la SDR est subdivisée.
Enfin, l'utilisateur notera que le tableau 1 du volume 1 de 1911 (Superficie et population en 1911 et en 1901) est quelque peu différent des autres tableaux. Le volume original contient certaines valeurs associées à plus d'une ligne et des lignes presque vides. Selon les directives générales de l'IRCS, il aurait fallu créer une rangée pour chaque SDR inscrite, bien que certaines d'entre elles n'aient eu aucune population en 1911. La référence choisie étant le tableau publié se rapportant à la population (répartie par sexe) pour l'année 1911, certaines valeurs d'origine sur la superficie de 1911 et sur la population de 1901 ont été déplacées dans le champ NOTES. Dans la mesure du possible, ces valeurs sont additionnées pour simplifier la création du tableau. Pour identifier ce type de cas, il suffit de chercher une accolade dans le champ du nom de la SDR ou de chercher les champs AREAS/POP_1901 dans les notes. Le fichier final étant un fichier plat, il aurait été difficile de faire autrement. L'utilisateur usera donc de précaution s'il veut utiliser les champs d'identification géographique et les effectifs de population de 1901 du tableau 1 du Volume 1 de 1911 en liaison avec les fichiers des polygones pour la construction de cartes thématiques ou pour l'analyse statistique directe des SDR de 1911.
Pour un aperçu de l'utilisation possible des tableaux publiés numérisés, consulter la page Utilisation de la composante spatiale de l'IRCS – Quelques exemples.
